在某三甲醫院的門(mén)診中,匯集了來(lái)自各地的病患,醫生們正在以最專(zhuān)業(yè)的能力和最快的速度進(jìn)行會(huì )診。期間,醫生與患者的對話(huà)可以通過(guò)語(yǔ)音識別技術(shù)被錄入到病例系統中,隨后大模型 AI 推理技術(shù)輔助進(jìn)行智能總結和診斷,醫生們撰寫(xiě)病例的效率顯著(zhù)提高。AI 推理的應用不僅節省了時(shí)間,也保護了患者隱私;
在法院、律所等業(yè)務(wù)場(chǎng)景中,律師通過(guò)大模型對海量歷史案例進(jìn)行整理調查,并鎖定出擬定法律文件中可能存在的漏洞;
……
以上場(chǎng)景中的大模型應用,幾乎都有一個(gè)共同的特點(diǎn)——受行業(yè)屬性限制,在應用大模型時(shí),除了對算力的高要求,AI 訓練過(guò)程中經(jīng)常出現的壞卡問(wèn)題也是這些行業(yè)不允許出現的。同時(shí),為確保服務(wù)效率和隱私安全,他們一般需要將模型部署在本地,且非常看重硬件等基礎設施層的穩定性和可靠性。一個(gè)中等參數或者輕量參數的模型,加上精調就可以滿(mǎn)足他們的場(chǎng)景需求。
而在大模型技術(shù)落地過(guò)程中,上述需求其實(shí)不在少數,基于 CPU 的推理方案無(wú)疑是一種更具性?xún)r(jià)比的選擇。不僅能夠滿(mǎn)足其業(yè)務(wù)需求,還能有效控制成本、保證系統的穩定性和數據的安全性。但這也就愈發(fā)讓我們好奇,作為通用服務(wù)器,CPU 在 AI 時(shí)代可以發(fā)揮怎樣的優(yōu)勢?其背后的技術(shù)原理又是什么?
1、AI 時(shí)代,CPU 是否已被被邊緣化?
提起 AI 訓練和 AI 推理,大家普遍會(huì )想到 GPU 更擅長(cháng)處理大量并行任務(wù),在執行計算密集型任務(wù)時(shí)表現地更出色,卻忽視了 CPU 在這其中的價(jià)值。
AI 技術(shù)的不斷演進(jìn)——從深度神經(jīng)網(wǎng)絡(luò )(DNN)到 Transformer 大模型,對硬件的要求產(chǎn)生了顯著(zhù)變化。CPU 不僅沒(méi)有被邊緣化,反而持續升級以適應這些變化,并做出了重要改變。
AI 大模型也不是只有推理和訓練的單一任務(wù),還包括數據預處理、模型訓練、推理和后處理等,整個(gè)過(guò)程中需要非常多軟硬件及系統的配合。在 GPU 興起并廣泛應用于 AI 領(lǐng)域之前,CPU 就已經(jīng)作為執行 AI 推理任務(wù)的主要硬件在被廣泛使用。其作為通用處理器發(fā)揮著(zhù)非常大的作用,整個(gè)系統的調度、任何負載的高效運行都離不開(kāi)它的協(xié)同優(yōu)化。
此外,CPU 的單核性能非常強大,可以處理復雜的計算任務(wù),其核心數量也在不斷增加,而且 CPU 的內存容量遠大于 GPU 的顯存容量,這些優(yōu)勢使得 CPU 能夠有效運行生成式大模型任務(wù)。經(jīng)過(guò)優(yōu)化的大模型可以在 CPU 上高效執行,特別是當模型非常大,需要跨異構平臺計算時(shí),使用 CPU 反而能提供更快的速度和更高的效率。
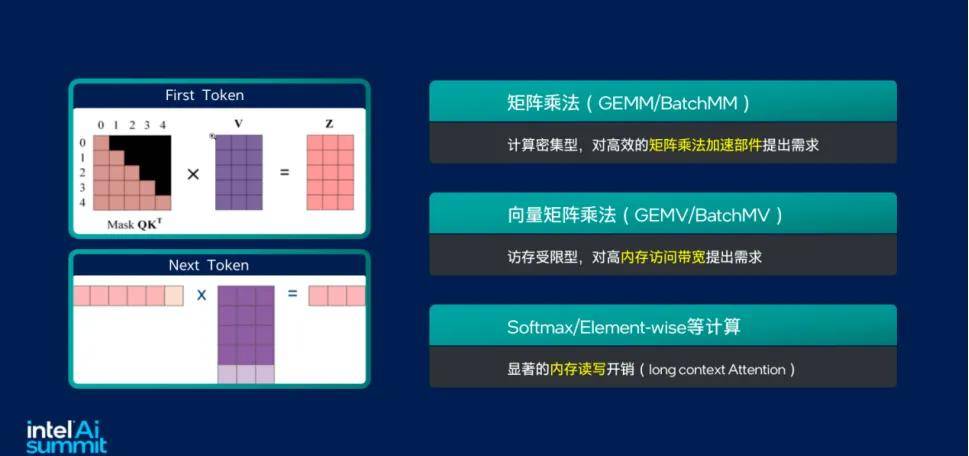
而 AI 推理過(guò)程中兩個(gè)重要階段的需求,即在預填充階段,需要高算力的矩陣乘法運算部件;在解碼階段,尤其是小批量請求時(shí),需要更高的內存訪(fǎng)問(wèn)帶寬。這些需求 CPU 都可以很好地滿(mǎn)足。
以英特爾舉例,從 2017 年第一代至強? 可擴展處理器開(kāi)始就利用英特爾? AVX-512 技術(shù)的矢量運算能力進(jìn)行 AI 加速上的嘗試;再接著(zhù)第二代至強? 中導入深度學(xué)習加速技術(shù)(DL Boost);第三代到第五代至強? 的演進(jìn)中,從 BF16 的增添再到英特爾? AMX 的入駐,可以說(shuō)英特爾一直在充分利用 CPU 資源加速 AI 的道路上深耕。
在英特爾? AMX 大幅提升矩陣計算能力外,第五代至強? 可擴展處理器還增加了每個(gè)時(shí)鐘周期的指令,有效提升了內存帶寬與速度,并通過(guò) PCIe 5.0 實(shí)現了更高的 PCIe 帶寬提升。在幾個(gè)時(shí)鐘的周期內,一條微指令就可以把一個(gè) 16×16 的矩陣計算一次性計算出來(lái)。另外,至強? 可擴展處理器可支持 High Bandwidth Memory (HBM) 內存,和 DDR5 相比,其具有更多的訪(fǎng)存通道和更長(cháng)的讀取位寬。雖然 HBM 的容量相對較小,但足以支撐大多數的大模型推理任務(wù)。
可以明確的是,AI 技術(shù)的演進(jìn)還遠未停止,當前以消耗大量算力為前提的模型結構也可能會(huì )發(fā)生改變,但 CPU 作為計算機系統的核心,其價(jià)值始終是難以被替代的。
同時(shí),AI 應用的需求是多樣化的,不同的應用場(chǎng)景需要不同的計算資源和優(yōu)化策略。因此比起相互替代,CPU 和其他加速器之間的互補關(guān)系才是它們在 AI 市場(chǎng)中共同發(fā)展的長(cháng)久之道。
2、與其算力焦慮,不如關(guān)注效價(jià)比
隨著(zhù)人工智能技術(shù)在各個(gè)領(lǐng)域的廣泛應用,AI 推理成為了推動(dòng)技術(shù)進(jìn)步的關(guān)鍵因素。然而,隨著(zhù)通用大模型參數和 Token 數量不斷增加,模型單次推理所需的算力也在持續增加,企業(yè)的算力焦慮撲面而來(lái)。與其關(guān)注無(wú)法短時(shí)間達到的算力規模,不如聚焦在“效價(jià)比”,即綜合考量大模型訓練和推理過(guò)程中所需軟硬件的經(jīng)濟投入成本、使用效果和產(chǎn)品性能。
CPU 不僅是企業(yè)解決 AI 算力焦慮過(guò)程中的重要選項,更是企業(yè)追求“效價(jià)比”的優(yōu)選。在大模型技術(shù)落地的“效價(jià)比”探索層面上,百度智能云和英特爾也不謀而合。
百度智能云千帆大模型平臺(下文簡(jiǎn)稱(chēng)“千帆大模型平臺”)作為一個(gè)面向開(kāi)發(fā)者和企業(yè)的人工智能服務(wù)平臺,提供了豐富的大模型,對大模型的推理及部署服務(wù)優(yōu)化積攢了很多作為開(kāi)發(fā)平臺的經(jīng)驗,他們發(fā)現,CPU 的 AI 算力潛力將有助于提升 CPU 云服務(wù)器的資源利用率,能夠滿(mǎn)足用戶(hù)快速部署 LLM 模型的需求,同時(shí)還發(fā)現了許多很適合 CPU 的使用場(chǎng)景:
●SFT 長(cháng)尾模型:每個(gè)模型的調用相對稀疏,CPU 的靈活性和通用性得以充分發(fā)揮,能夠輕松管理和調度這些模型,確保每個(gè)模型在需要時(shí)都能快速響應。
●小于 10b 的小參數規模大模型:由于模型規模相對較小,CPU 能夠提供足夠的計算能力,同時(shí)保持較低的能耗和成本。
●對首 Token 時(shí)延不敏感,更注重整體吞吐的離線(xiàn)批量推理場(chǎng)景:這類(lèi)場(chǎng)景通常要求系統能夠高效處理大量的數據,而 CPU 的強大計算能力和高吞吐量特性可以很好地滿(mǎn)足要求,能夠確保推理任務(wù)的快速完成。
英特爾的測試數據也驗證了千帆大模型平臺團隊的發(fā)現,其通過(guò)測試證明,單臺雙路 CPU 服務(wù)器完全可以輕松勝任幾 B 到幾十 B 參數的大模型推理任務(wù),Token 生成延時(shí)完全能夠達到數十毫秒的業(yè)務(wù)需求指標,而針對更大規模參數的模型,例如常用的 Llama 2-70B,CPU 同樣可以通過(guò)分布式推理方式來(lái)支持。此外,批量處理任務(wù)在 CPU 集群的閑時(shí)進(jìn)行,忙時(shí)可以處理其他任務(wù),而無(wú)需維護代價(jià)高昂的 GPU 集群,這將極大節省企業(yè)的經(jīng)濟成本。
也正是出于在“CPU 上跑 AI”的共識,雙方展開(kāi)了業(yè)務(wù)上的深度合作。百度智能云千帆大模型平臺采?基于英特爾? AMX 加速器和大模型推理軟件解決方案 xFasterTransformer (xFT),進(jìn)?步加速英特爾? 至強? 可擴展處理器的 LLM 推理速度。
3、將 CPU 在 AI 方面的潛能發(fā)揮到極致
為了充分發(fā)揮 CPU 在 AI 推理方面的極限潛能,需要從兩個(gè)方面進(jìn)行技術(shù)探索——硬件層面的升級和軟件層面的優(yōu)化適配。
千帆大模型平臺采用 xFT,主要進(jìn)行了以下三方面的優(yōu)化:
●系統層面:利用英特爾? AMX/AVX512 等硬件特性,高效快速地完成矩陣 / 向量計算;優(yōu)化實(shí)現針對超長(cháng)上下文和輸出的 Flash Attention/Flash Decoding 等核心算子,降低數據類(lèi)型轉換和數據重排布等開(kāi)銷(xiāo);統一內存分配管理,降低推理任務(wù)的內存占用。
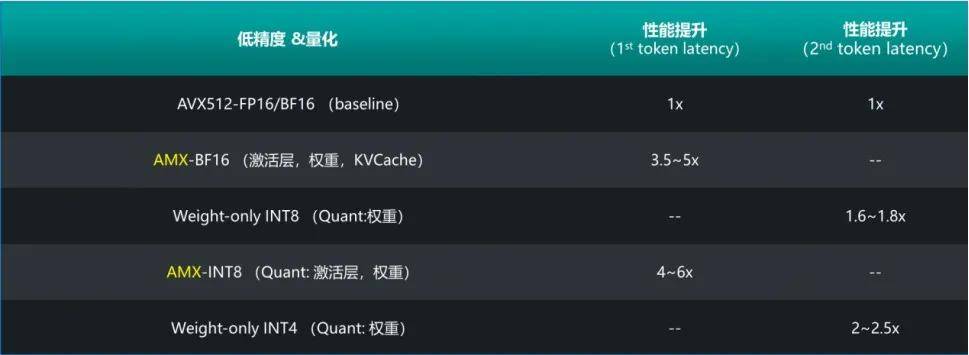
●算法層面:在精度滿(mǎn)足任務(wù)需求的條件下,提供多種針對網(wǎng)絡(luò )激活層以及模型權重的低精度和量化方法,大幅度降低訪(fǎng)存數據量的同時(shí),充分發(fā)揮出英特爾? AMX 等加速部件對 BF16/INT8 等低精度數據計算的計算能力。
●多節點(diǎn)并行:支持張量并行(Tensor Parallelism)等對模型權重進(jìn)行切分的并行推理部署。使用異構集合通信的方式提高通信效率,進(jìn)一步降低 70b 規模及以上 LLM 推理時(shí)延,提高較大批處理請求的吞吐。
第五代至強? 可擴展處理器能在 AI 推理上能夠取得如此亮眼的效果,同樣離不開(kāi)軟件層面的優(yōu)化適配。為了解決 CPU 推理性能問(wèn)題,這就不得不提 xFT 開(kāi)源推理框架了。
xFT 底層適用英特爾 AI 軟件棧,包括 oneDNN、oneMKL、IG、oneCCL 等高性能庫。用戶(hù)可以調用和組裝這些高性能庫,形成大模型推理的關(guān)鍵算子,并簡(jiǎn)單組合算子來(lái)支持 Llama、文心一言等大模型。同時(shí),xFT 最上層提供 C++ 和 Python 兩套便利接口,很容易集成到現有框架或服務(wù)后端。
xFT 采用了多種優(yōu)化策略來(lái)提升推理效率,其中包括張量并行和流水線(xiàn)并行技術(shù),這兩種技術(shù)能夠顯著(zhù)提高并行處理的能力。通過(guò)高性能融合算子和先進(jìn)的量化技術(shù),其在保持精度的同時(shí)提高推理速度。此外,通過(guò)低精度量化和稀疏化技術(shù),xFT 有效地降低了對內存帶寬的需求,在推理速度和準確度之間取得平衡,支持多種數據類(lèi)型來(lái)實(shí)現模型推理和部署,包括單一精度和混合精度,可充分利用 CPU 的計算資源和帶寬資源來(lái)提高 LLM 的推理速度。
另外值得一提的是,xFT 通過(guò)“算子融合”、“最小化數據拷貝”、“重排操作”和“內存重復利用”等手段來(lái)進(jìn)一步優(yōu)化 LLM 的實(shí)現,這些優(yōu)化策略能夠最大限度地減少內存占用、提高緩存命中率并提升整體性能。通過(guò)仔細分析 LLM 的工作流程并減少不必要的計算開(kāi)銷(xiāo),該引擎進(jìn)一步提高了數據重用度和計算效率,特別是在處理 Attention 機制時(shí),針對不同長(cháng)度的序列采取了不同的優(yōu)化算法來(lái)確保最高的訪(fǎng)存效率。
目前,英特爾的大模型加速方案 xFT 已經(jīng)成功集成到千帆大模型平臺中,這項合作使得在千帆大模型平臺上部署的多個(gè)開(kāi)源大模型能夠在英特爾至強? 可擴展處理器上獲得最優(yōu)的推理性能:
●在線(xiàn)服務(wù)部署:用戶(hù)可以利用千帆大模型平臺的 CPU 資源在線(xiàn)部署多個(gè)開(kāi)源大模型服務(wù),這些服務(wù)不僅為客戶(hù)應用提供了強大的大模型支持,還能夠用于千帆大模型平臺 prompt 優(yōu)化工程等相關(guān)任務(wù)場(chǎng)景。
●高性能推理:借助英特爾? 至強? 可擴展處理器和 xFT 推理解決方案,千帆大模型平臺能夠實(shí)現大幅提升的推理性能。這包括降低推理時(shí)延,提高服務(wù)響應速度,以及增強模型的整體吞吐能力。
●定制化部署:千帆大模型平臺提供了靈活的部署選項,允許用戶(hù)根據具體業(yè)務(wù)需求選擇最適合的硬件資源配置,從而優(yōu)化大模型在實(shí)際應用中的表現和效果。
4、寫(xiě)在最后
對于千帆大模型平臺來(lái)說(shuō),英特爾幫助其解決了客戶(hù)在大模型應用過(guò)程中對計算資源的需求,進(jìn)一步提升了大模型的性能和效率,讓用戶(hù)以更低的成本獲取高質(zhì)量的大模型服務(wù)。
大模型生態(tài)要想持續不斷地往前演進(jìn),無(wú)疑要靠一個(gè)個(gè)實(shí)打實(shí)的小業(yè)務(wù)落地把整個(gè)生態(tài)構建起來(lái),英特爾聯(lián)合千帆大模型平臺正是在幫助企業(yè)以最少的成本落地大模型應用,讓他們在探索大模型應用時(shí)找到了更具效價(jià)比的選項。
未來(lái),雙方計劃在更高性能的至強? 產(chǎn)品支持、軟件優(yōu)化、更多模型支持以及重點(diǎn)客戶(hù)聯(lián)合支持等方面展開(kāi)深入合作。旨在提升大模型運行效率和性能,為千帆大模型平臺提供更完善的軟件支持,確保用戶(hù)能及時(shí)利用最新的技術(shù)成果,從而加速大模型生態(tài)持續向前。
更多關(guān)于至強? 可擴展處理器為千帆大模型平臺推理加速的信息,請點(diǎn)擊英特爾官網(wǎng)查閱。
免責聲明:市場(chǎng)有風(fēng)險,選擇需謹慎!此文僅供參考,不作買(mǎi)賣(mài)依據。
關(guān)鍵詞:








